This is a guest written article by Mike Taylor.
Mike co-founded a 50-person marketing agency called Ladder, has created marketing & AI courses on LinkedIn, Vexpower, and Udemy taken by over 400,000 people, and published a book with O’Reilly on prompt engineering. He builds AI products at Brightpool.dev.
If data is publicly available to browse on the internet, then it’s possible to get that data and structure it into a spreadsheet. As a marketer you often need to collect data from your client’s websites to generate thousands of PPC ads, especially as internal tech teams are often operating at full capacity, making it difficult for them to provide everything the marketing team would like to see in a structured product feed.
The difficulty with gathering this data is that every website is built differently, and so you always have to write some custom code to extract the information. The introduction of generative AI tools like ChatGPT has made writing custom code like this incredibly easy. There’s no substitute for a proper development process with rigorous testing and QA, but AI has made it trivial to spin up a prototype of a new idea in a few hours. As an early adopter of AI and co-author of Prompt Engineering for Generative AI (released June 2024 through O’Reilly), I’ve been using AI to prototype new ideas for a while, and thought it’d be useful to share my process.
1. Come up with a product feed idea
It’s rare that I’m building a product feed from scratch, as in many cases my client already has a product feed, and I’m just supplementing it with additional fields they don’t have yet. Either way, extracting the data myself is only meant as a temporary solution, to prove the value of using these attributes in our ads, so that the tech team can implement a more permanent and scalable internal solution. It’s easier to demonstrate the value of a new idea when you can show a proof of concept implementation, and you learn what the potential issues will be to help inform your tech team’s approach when they build the real thing.
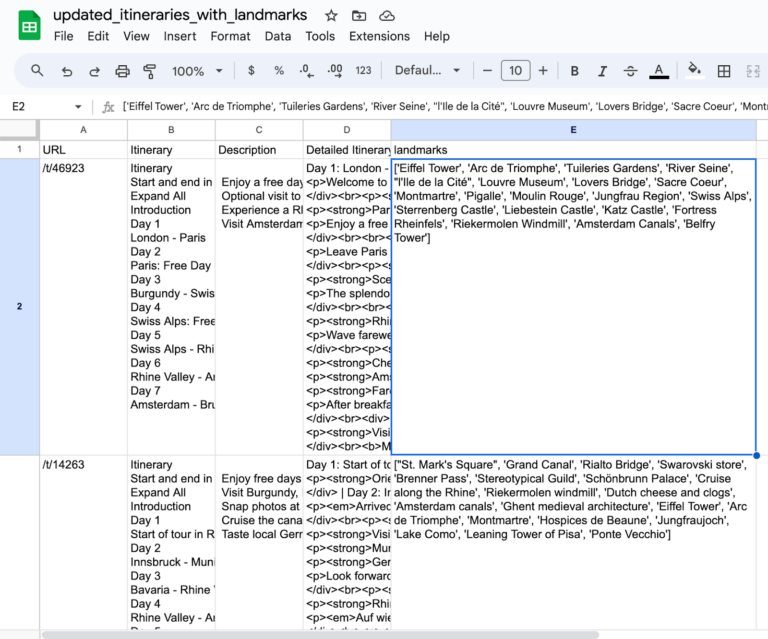
The website we’re extracting information from is TourRadar Adventures, who already have a well-defined product feed that WeDiscover is using to automate their ads. I’m on the outside here, so I don’t have access to any client information or their feed, but I wanted to use a real client that I knew they had, in order to make my AI demonstration relevant to the WeDiscover team. I noticed that TourRadar had tour pages with these fantastic itinerary sections, which contain lots of unstructured data that could be useful in ads. The proof of concept would be to extract different landmarks like ‘Eiffel Tower’ and ‘Arc de Triomphe’ which could then be put into the ad copy automatically to see if it increased the clickthrough rate on ads.
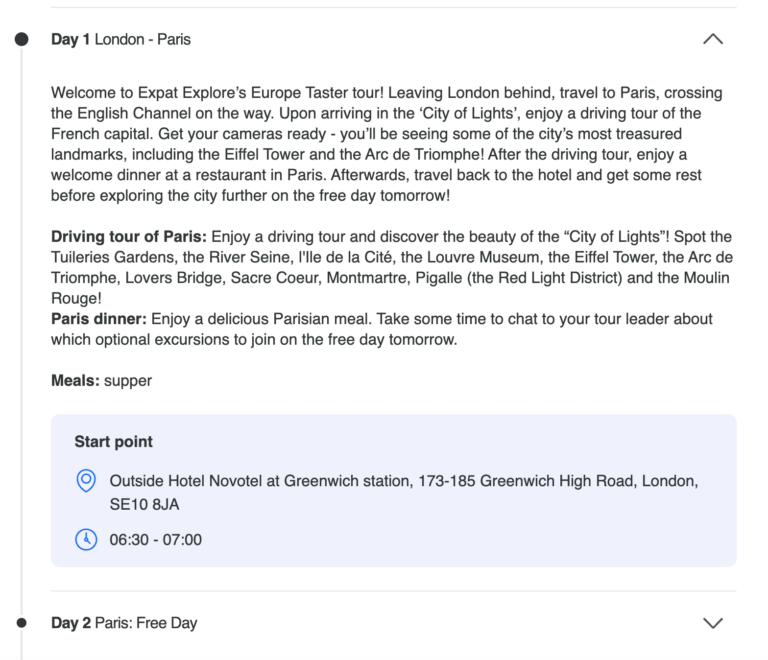
2. Find a collection page or sitemap
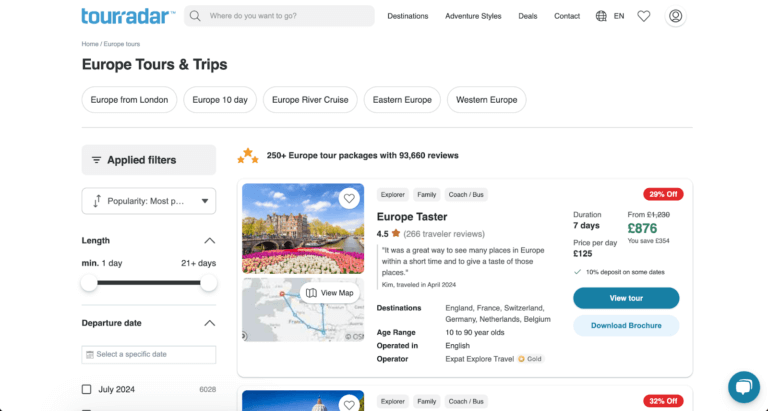
Once you know what website you want to extract information from, and what information on the pages would be useful, the next step is to zoom out and find a list of those pages you can loop through. Often this is the sitemap that websites put together for SEO (which often lives at www.examples.com/sitemap.xml), but in this case I couldn’t find exactly what I was looking for. So I turned to the category pages on the website which list tours for specific regions, and gave myself the goal of testing this on all the tours for the Europe Tours & Trips category. Normally you’d also go another step up and find a list of category pages as well, but for my proof of concept this one category worked fine.
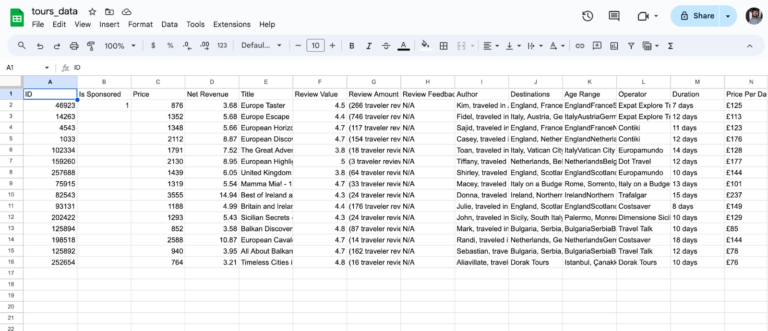
Now every website is built differently, and we need to see what we’re dealing with. Right click on the section of the website you want to get data from and then click “Inspect” (using Chrome). This opens up a pane that shows the website code, and highlights the HTML element you’re hovering over. I can see that the tours are in an unordered list element <ul>, with each tour being a list element <li>.
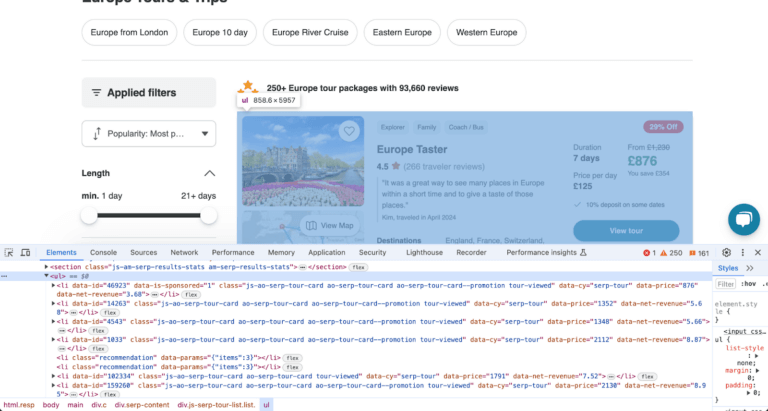
If you know how to code, you can spend some time writing a script to parse the different list elements representing the tours, and then export it into a CSV. However, writing that code is custom for every website and might take some time. The script we write will go out of date and break any time they decide to update the structure of their website. And we’re only doing this as a proof of concept; once proven this then justifies valuable tech resource being spent on adding this information to the feed as a long term solution. This sort of throwaway code is the perfect task for ChatGPT, which needs very little instruction: just the copy and paste HTML and a command to write python to get these list elements and save them in a CSV.

ChatGPT comes back quickly with a script I can run to extract the list elements, that you can review to understand what it does before running it. If you don’t understand a specific line, ChatGPT can often give you a satisfactory explanation, or make corrections if you ask it. Typically I run these scripts in a Google Colab notebook which provides an isolated computer in the cloud, so I can’t really mess anything up (worst case scenario Google just terminates my session). In this case the AI has recommended we use BeautifulSoup, a common HTML parsing library, and has written all the complicated parsing logic.
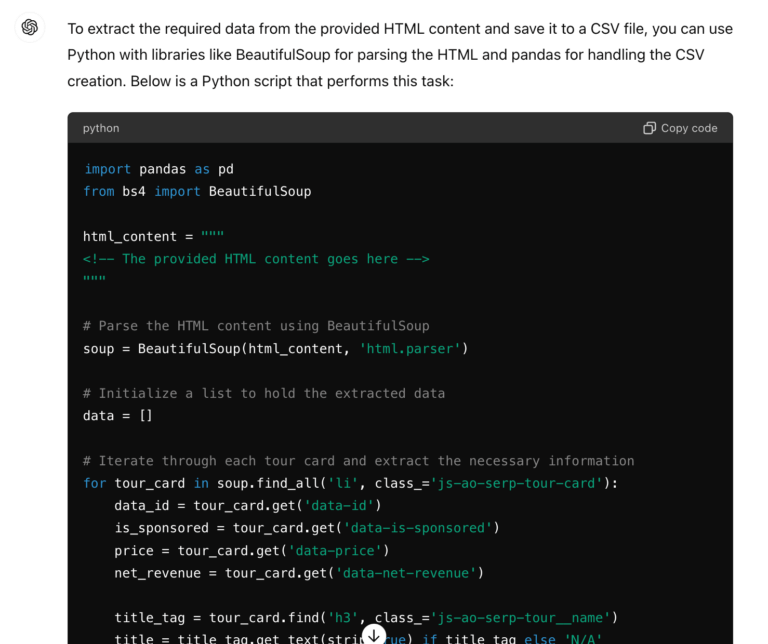
Note that ChatGPT will often put placeholders in the code, so you do need to edit these parts of the script before it’ll work. In this case it has put a placeholder string <!– The provided HTML content goes here –> which we just need to copy and paste our HTML into for this to run. Sometimes it will tell you to install specific libraries like !pip install beautifulsoup4, or add your API key to use a service like OpenAI (it’s like a password for your code to use to log in – you can usually find one in your account profile). In this case we just run the script then download the CSV, and it works first time!
3. Identify the content on the page you need
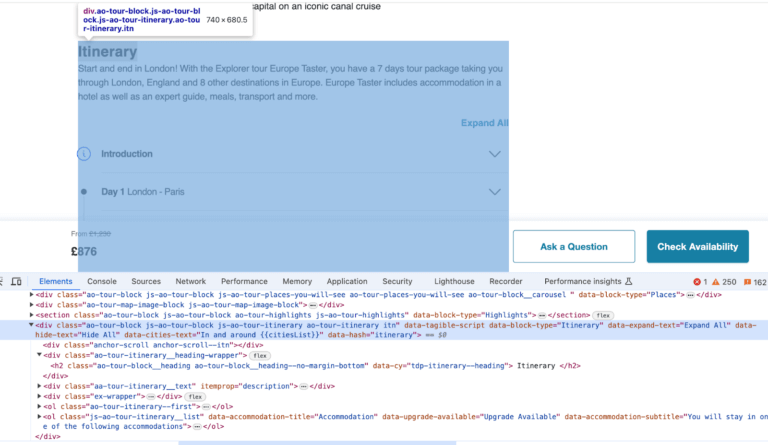
Now we have a list of pages to iterate through, we need to define what content on the page we want to extract. This was the Itinerary section specifically, which had all of those rich descriptions wanted to extract landmarks from. One thing I don’t recommend is copy and pasting the full HTML of the page into ChatGPT because with all the superfluous tags and code in the header of the website you are likely to run into the token limit for ChatGPT. Tokens are ~3/4th of a word, and ChatGPT can handle 128,000 tokens in a single chat session, or approximately the length of a Harry Potter book, but that is used up quite quickly with all the code modern websites have. Just right click on the element you want and select Inspect to see the content you need.
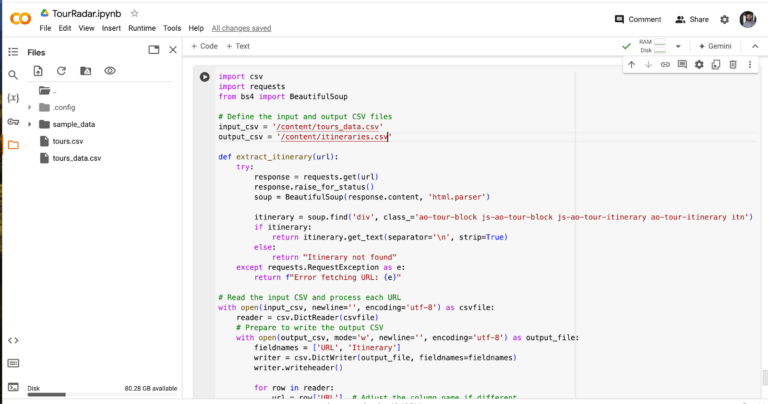
Now we want to give ChatGPT the context of both the HTML content we just copied, and also the structure of the spreadsheet we created containing the list of URLs. You can upload files to ChatGPT so I just export the CSV and upload it into the chat message.

Again, I’m running the script in a Google Colab notebook, which means I need to upload that CSV here too. If you don’t see the filesystem make sure you’re connected to a runtime, which you can do by clicking connect in the top right corner, or attempting to run the code. In the filesystem on the left you can upload a file and then right click on it and choose Copy path. That’s all I needed to change to fill in the input_csv variable in the script ChatGPT wrote for me.
4. Mitigate any complicated or complex features
Unfortunately now we’re facing a problem. The Itineraries we’re getting are incomplete. We only got the headlines Day 1 London – Paris instead of those rich descriptions we were interested in.
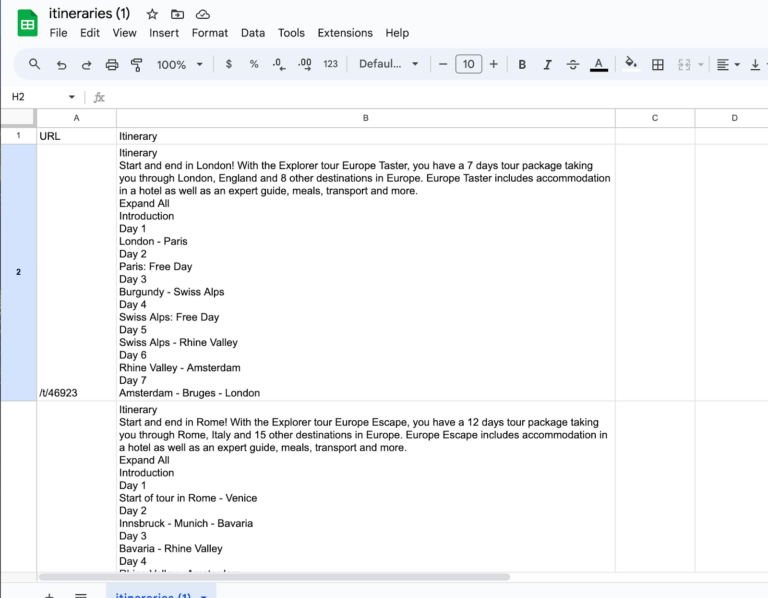
On further investigation, this is because those snippets aren’t actually on the page until you click to expand the carousel (by clicking on one of the Days, or clicking Expand All). It’s common on dynamic websites these days that you don’t get the full content of the website on load, and that makes getting the information slightly harder. Thankfully most of the time you can simply look at the network calls that the website is making to get that content. After right clicking on the page and going to Inspect, you can click over to the Network tab from the default Elements tab. Then click on the Expand All button and see what shows up. When I click on the top network request and look at the Preview, I can see it contains all the information I need.
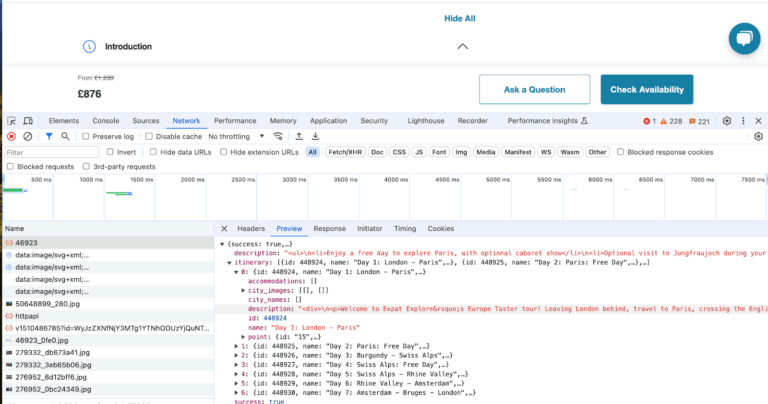
Looking at the URL that request is sent to, it’s a fairly simple structure. You just take the base URL https://www.tourradar.com/api/tour/itinerary/ and then add the ID of the tour to the end 46923. Some requests are more complicated than others, and require more complicated methods to access, for example adding a user authentication cookie to the request, or loading a virtual browser or WebDriver like Selenium. Thankfully this API works just by visiting it, which we can test by pasting the URL into Chrome. We can see it has the extra information we need.

We repeat the sort of prompt we used last time to get the information from the URL, except this time we ask ChatGPT to visit the URL endpoint we just discovered. It helps to give it an example of the response so it knows what it’s working with. That gives us a script we can then run in our Google Colab notebook and it will add to the CSV to update it with the additional information.

5. Feed errors back into ChatGPT to find a fix
This is when we run into our first error! It’s pretty amazing that we’ve gotten this far without any mistakes in the code, but mistakes like this are happening less and less as these models get smarter. In this case the script tries to parse the HTML content into a DataFrame (to turn it into a CSV), and that conversion is failing. Let’s say we didn’t know that was the issue: we can just paste the error into ChatGPT.
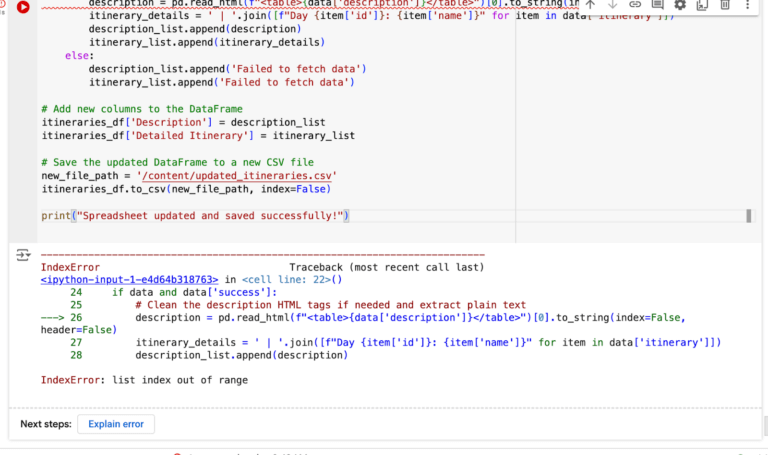
Make sure you paste the error into the same chat where it created the code in the first place, so it has the full context of the problem. I find fairly often that it can diagnose its own issues, but you may need to provide additional context, like asking it to browse the internet to find a solution, or copy and pasting the documentation for the library you are using. In this case it diagnoses correctly with no additional context, and rewrites our script for us.

The script works fine now, although we can keep adjusting it if we’re not happy with the output. We finally have a spreadsheet with all of the information we wanted in it, which means the hard part is over! Now we just need to figure out what to extract from this unstructured information, using an LLM.
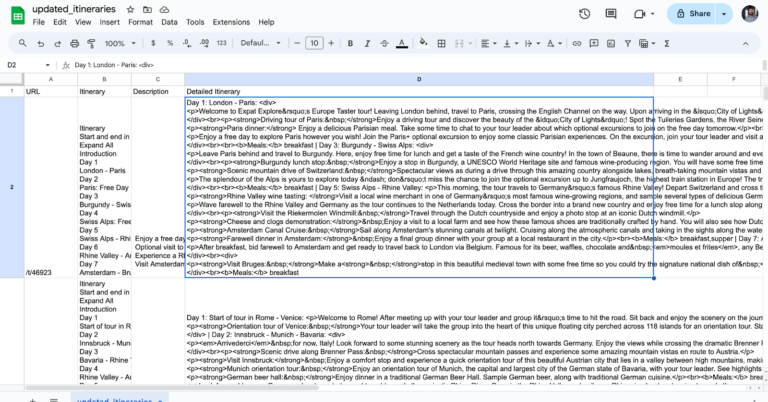
6. Use an LLM to extract new fields from unstructured data
Now for the fun part, using AI to extract structured data. For this I like to use the instructor library, which is a lightweight framework that makes it easier to get structured data back from LLMs. It is designed to map to exactly how you would normally call the OpenAI API, but you get a Python class back as a response (instead of having to write custom parsing code). For newer libraries ChatGPT doesn’t always know enough about them in its training data, so I like to copy and paste the documentation into my prompt, in this case just the readme.md file in the instructor GitHub repository.

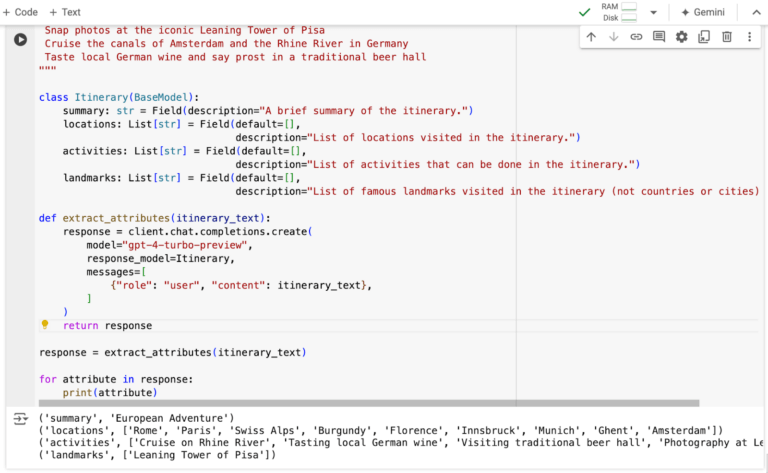
To keep things simple, and easy to see what the library is doing and if it’s working, I just used a short itinerary description, rather than the full detailed itinerary. The way instructor works is that you specify a Pydantic model first (similar to a Python class), and then pass that into the chat completion as a response_model. Then the instructor library will automatically convert that into instructions in the prompt for you, so you don’t have to worry about anything other than defining the model. In this case we just ask it to provide a list of landmarks in the itinerary. Note that the instructor library needs the openai_api_key to log into your OpenAI account and call GPT-4, which you can find here. If you want to follow along, all the code is in this Google Colab notebook.
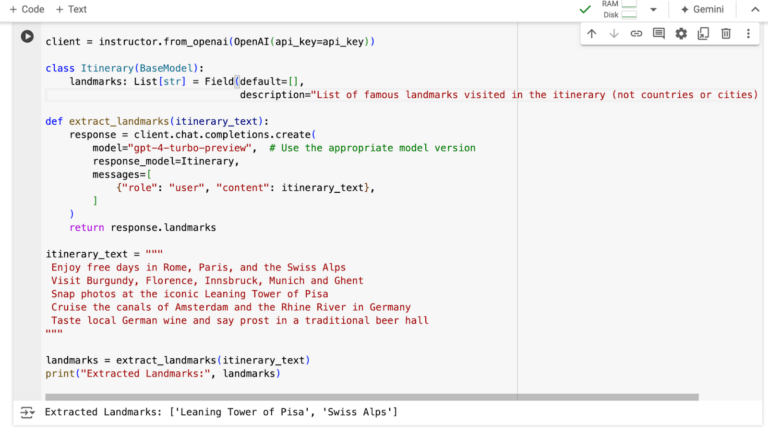
Now that we have our instructor call working, we just need to apply that function to all of the rows in the dataframe, which is relatively straightforward. With larger files you might want to specify the logic for retrying failed requests, which the instructor library also makes easy. A good example can be found in their GitHub repository. Our updated script works perfectly, and we get a good list of landmarks as an additional column on the spreadsheet. We can adjust the script to put these in whatever format we like, and we now have great additional information to inject into our ads.
Now all of this setup pays off, because the beauty of the instructor library is that extracting additional information is as easy as adjusting our Itinerary model. I simply add a summary, list of activities, and a list of locations to the model, and run it again, and all of these things are extracted in an easy to parse format. This is as close to magic as you can get, because we can work with LLMs in a more deterministic and easy to maintain way.
While there are plenty of flashy demos of people using AI on social media, I find the majority of real-world AI workloads are tasks like this. LLMs are fantastic at extracting structured information from unstructured data, which is something that would normally take a human a long time to do manually. These jobs can be run at scale with retry logic in case anything goes wrong, as part of a traditional data engineering pipeline. Using ChatGPT to write our custom code got us up and running in just under an hour, and the instructor library made the AI extraction part easy. As these models get better and the frameworks for using them improve, it’s not unreasonable to expect that you can take anything from a client’s website and transform it into any format you need. What use cases would that open up in your organisation?