
Reducing Cross Matching to Increase CVR by 19%
Reducing Cross Matching to Increase CVR by 19%
A Lyst & WeDiscover Case Study

Share
Context
Imagine navigating the vast ocean of global fashion with over 17 million products from more than 20,000 brands, complicated by constantly shifting availability and trends. Welcome to the world of Lyst: a colossal fashion-focused affiliate business dealing with an ever-changing inventory that reaches customers across the globe.
Seasonality isn’t as straightforward as you may think here. On a given day you may be heavily promoting winter clothing in the U.S., whilst simultaneously pushing summer wear in Australia. Mind-boggling, isn’t it?
This posed a unique challenge for managing paid search at Lyst and left them looking for a way to update their account structure that meant their activity could:
-
- Effectively target an immense range of products and brands.
- Achieve volume goals whilst still operating within tight profitability margins.
- Be manageable within a single account for each market.
- Direct traffic precisely to appropriate brand/ category-specific landing pages.
- Be repeatable and scalable across markets.
The Lyst team were looking for a way that would take away the manual nature of negative keyword extraction that had been occurring to date. The human element involved there (both in terms of limited frequency of monitoring as well as semantic biases) meant that effective checks and balances were lacking in how negative keyword combinations between campaigns, ad groups and match types were chosen.
They then created a refined account structure created off the back of this was straightforward:
-
- One campaign per category (e.g. ‘Shoes’).
- One ad group per brand (e.g. ‘Nike’).
- Broad keywords encompassing both category and subcategories (such as ‘Nike shoes’ and ‘Nike boots’).
- Utilising keyword-level landing pages to take customers to highly relevant pages.
The Challenge: Cross Matching
The refined account structure mirrored Lyst’s sitemap and fit neatly into a single account. So, where was the opportunity?
When analysing Lyst’s Google Ads setup, the WeDiscover team noticed a challenge: in the search query report, lots of queries that were not the most relevant match available within the account were matching to broad keywords. This meant that users were not always being shown the ads and landing pages most relevant to them.
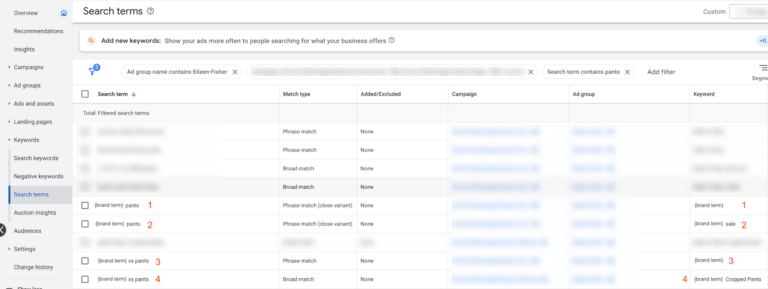
In the example above, notice how search queries 1 and 2 are the same, but they are each attached to 2 different broad keywords. And what about search queries 3 and 4? Again, the same search query, but with each matching to 2 different keywords. Incidentally not one of those keywords was the ideal one for those search terms to be matching to, given that the account already included the keyword `[brand term] pants` anyway – a much better match to all these search queries!
So why would google match the same search query to different keywords? While we can’t be sure of the exact reason in each scenario, there are a few possibilities:
Cross Match Analysis: Unveiling Search Query Matching Behaviour
Exploring the intricacies of search query matching behaviour led the us to develop a Cross Match Analysis. The objective of the cross match analysis was to understand how many non-optimal search query to keyword matches exist within the account.
We counted these non-optimal search query to keyword matches as being any search query matched to a keyword when there was a more relevant keyword live within the account.
In order to calculate non-optimal matches we:
-
- Compared every search query to every keyword
- Calculated a score that reflected how close the words/phrases are
- Selected the highest scored match
- Compared the selected high scoring match with Google’s matched keyword (if they were the same, that was then classed as a good match)
- Tagged results to the search query (non-optimal/ optimal)
The biggest challenge across all of the above lay in selecting a method that accurately scored the match. This task is typically called `semantic similarity`.
Scoring Semantic Similarity: A Look Into Our Approach
As with many data science tasks we had to test various different approaches, evaluate each approach performance and iterate on it. Calculating semantic similarity is a very complex task, and there is no standard approach across the industry. The complexity comes because words can have multiple meanings.
Example
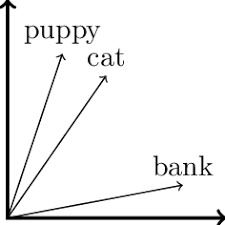
Consider that you are a company operating in the finance sector, looking at the word ‘`bank`’. Bank has multiple meanings, it could be a financial institution, or the ground that borders a river. So if you had the search query “river bank near me”, should that be matched to the broad keyword “cross river”?
Perhaps it might seem like it shouldn’t – but it’s actually not necessarily a bad match. Cross River is the name of a financial bank, and River Bank is also the brand name of a financial bank. So this would in fact be a good match for targeting a competitor.
We explored various known approaches to scoring semantic similarity, including custom made solutions and eventually opted for a text-to-embeddings transformation combined with cosine similarity scoring solution. We used an OpenAI text-to-embeddings model (also used in ChatGPT) to transform every search query and keyword into a high dimensional array representation of the search query and keyword. Basically a dot in the space. After transforming the whole account into embeddings, we then had a cloud of dots in the space.
Within these dots we had search queries and keywords. We could then calculate the distance between those dots using cosine similarity (a fancy way of calculating distance based on angles). Voila! The closest dots shown are the closest search query to keyword match.
High Cross Matching: A Significant Challenge in Lyst's Account Structure
As mentioned, we had found the Lyst account to be prone to high cross matching given its structure. Specifically, our analysis revealed a 70% cross-matching issue, indicating a significant number of search queries were being associated with semantically similar but not always accurate keywords. For instance, a search for ‘Nike flip flops’ could inadvertently land under ‘Nike clothing’ (broad match type), leading to misdirected traffic due to the keyword-level landing pages.
The issue was caused by two types of cross-matching:
-
- Cross-campaign matching: this occurred when two campaigns (such as Shoe and Clothing campaigns) had similar broad keywords, resulting in activity crossing the campaign classification. For example, Shoe search queries would match clothing keywords, and vice versa.
- Cross-keyword matching within ad group: within the same ad group, we had similar keywords, ranging from the more precise and targeted to broader keywords. Some of the cross-matching was due to search queries being matched to the broader keyword, even if it was an exact match to a more precise keyword. For instance, a search query for Nike boots would match to the Nike shoes keyword instead of the Nike boots keyword.
Given Lyst operates across 17 million products within 170 countries, this was presenting a significant problem for Lyst. It hampered the account structure’s ability to effectively direct activity to the correct ad copy and landing pages, which was then negatively impacting performance via metrics like CTR and CVR.
Achieving Success: Targeted Strategies To Reduce Cross Matching & Improve Performance
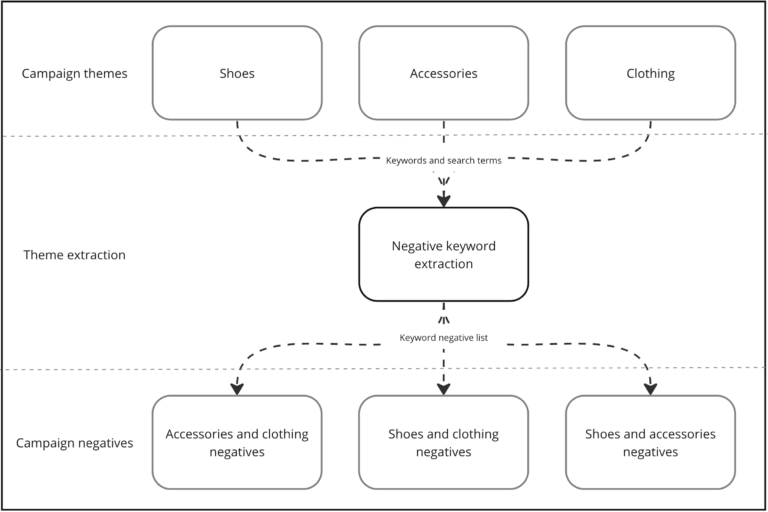
Working together with the Lyst team, we implemented a targeted negative keyword strategy to address the issue of cross-campaign matching. To achieve this, we began by analysing every keyword and search query within each campaign, to get a view of the campaign theme. We then used that theme to create an optimal set of themed keywords that, when used as broad match, overlapped as much of the campaign search space as possible.
Using each campaign’s themed keywords as broad negative keywords in all other campaigns enabled us to negate spaces that were already covered by other campaigns, thus reducing cross matching.
In the past, achieving a solid negative keyword strategy posed difficulties in the way a very vast number of keyword variations had to be considered, even when adding broad negative keywords. As broad matching expands to encompass ever more search terms – although this can present problems when used in a targeting capacity – it is now easier than ever before to negate a whole theme without the need for as many keyword variations.
That setup can be illustrated in the following example:
-
- For the Shoes campaign, we created a comprehensive list of keywords that covered the area we wanted to reach within that campaign.
- We then took those keywords and applied them as negatives to all other campaigns e.g. Accessories and Clothing. This ensured those campaigns did not begin to funnel traffic away from the Shoes campaign in instances where it would be most relevantly directed there, thus reducing cross-matching.
We designed a pre-post experiment to obtain statistically significant results on the impact of those changes then analysed the results using the following approaches, alongside a further cross matching analysis:
The analysis found that as a result of the changes made, cross-matching was reduced from ~75% to ~25%. It also refined the user journey; directing searches more accurately to their intended ad copy and landing pages.
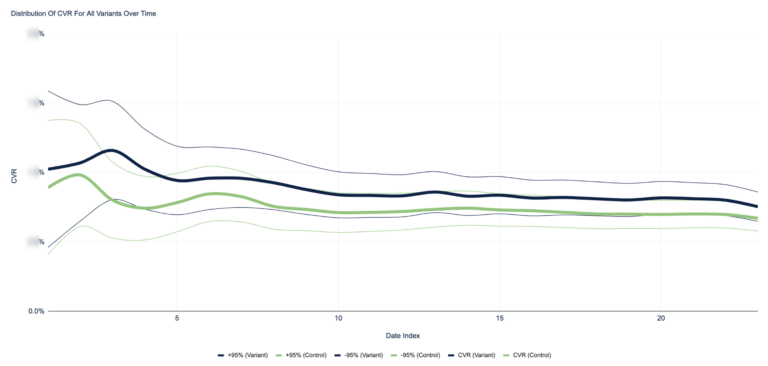
This had a notable positive impact on both CTR and CVR, as demonstrated by the graph below, showing CTR pre and post implementing the change on September 6th. Notice the counterfactual – the control group that did not follow the new negative keyword structure – always trailing below the variant group. That represents a statistically significant improvement of 9.8% in click-through rate – across the whole the account!
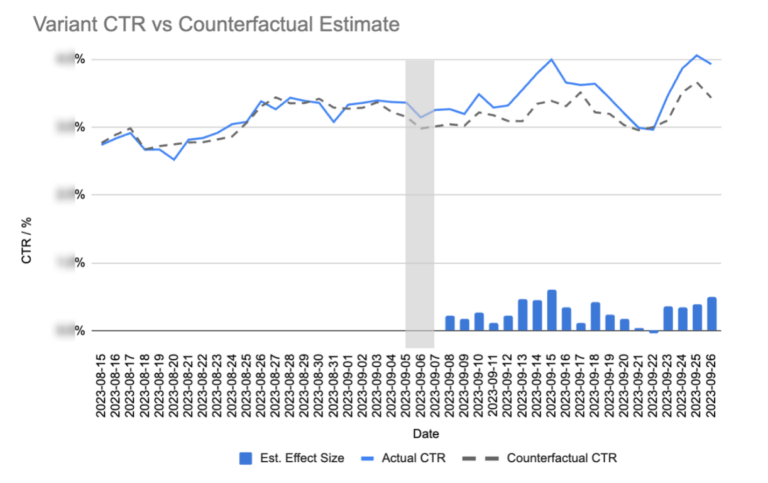
The impact in CVR was even more dramatic: a statistically significant 19% increase in CVR was seen for the variant group. The graph below shows the variant and control group across a date index of the post period. The variant group sits consistently above the control, whilst remaining within a 95% confidence interval.
Closing Thoughts
The concepts of interconnectedness, synthesis, feedback loops and causality were all at play within this project.
What we aimed to test wasn’t rooted in Google’s ‘best practice’ but rather an understanding of how we could adapt activity to best suit the needs of the account. The dynamic nature of inventory within the Lyst account dictated a unique approach, as showcased during their first revamp of their account structure prior to undertaking this joint venture, when small wins were made in some areas, but operational control was lost in others.
As Chris Watson-Shaw, VP, Growth Marketing stated: “what [Lyst] wanted for this project was divergent thinking to help our team validate trade-offs between operational efficiency and keyword to landing page relevancy, evaluating how Lyst can best benefit from Google’s match type architecture. We knew there was no perfect answer to our problem due to the scale of inventory but we appreciated the benefits of advanced technology solutions to elevate operations”.
This case study illustrates the power of deep industry knowledge combined with focused analysis and strategic testing. We’re excited to continue our journey with Lyst, pushing boundaries and discovering more innovative solutions in the ever-evolving world of digital advertising.